On the other side of a very hard problem is a very big opportunity.
A Story in Three Parts
I think there are only two consequential software products to work on over the next decade:
- Create state-of-the-art foundation models and their infrastructure
- Rebuild legacy applications as AI-native platforms designed for agents
At DOSS, we are doing both.
Right now we’re witnessing the dawn of an Industrial Revolution for knowledge work. Human intelligence is reproducibly scalable through electricity and etched silicon.
I believe it will be an even greater transformation than what we saw in the 19th century – this time around, the factories will be building and operating themselves.
Two years ago, I wrote a list of hard problems and bet the company on solving them so that we could participate in this revolution.
- Act I: Build an Operations Cloud for teams that work in the real world.
- Act II: Build self-driving software for The Enterprise.
- Act III: Build a world model of The Enterprise.
Today we’re announcing our transition from Act I to Act II and publishing our next list of hard problems.
Before we dive in, let’s rewind and set the stage: how did we get here? Where did all this Enterprise Software come from?
A Brief History of Enterprise Software
_imageabe.png)
First off, let’s get this part straight: when I say Enterprise Software, I’m specifically referring to applications software
You could be pedantic and say “Enterprise Applications,” since I’m excluding pure-play infrastructure (data platforms, “neo-clouds,” etc.) and cybersecurity.
Since the advent of computers, there have been three canonical generations of enterprise applications. Each generation solved its era’s deployment problem, but none addressed the upgrade and customization problem. Gen4 is now beginning to solve both.
Gen1 - Mainframe

This era was about “the system”... cost-prohibitive to a degree that only the government, large banks, and a few corporations could afford. Mainframe computers quickly became mission-critical for payroll, bank balances, running the U.S. Census, etc. They were physically massive, taking up entire rooms and operated by teams of trained professionals with a limited set of programs.
Ex: IBM, SAP
Qualities:
- Software was deployed with proprietary hardware
- Application behavior was literally soldered into the hardware abstractions
- Customization was necessary and permanent
- Upgrades required swapping hardware entirely
Gen2 - Networked (Client-Server)
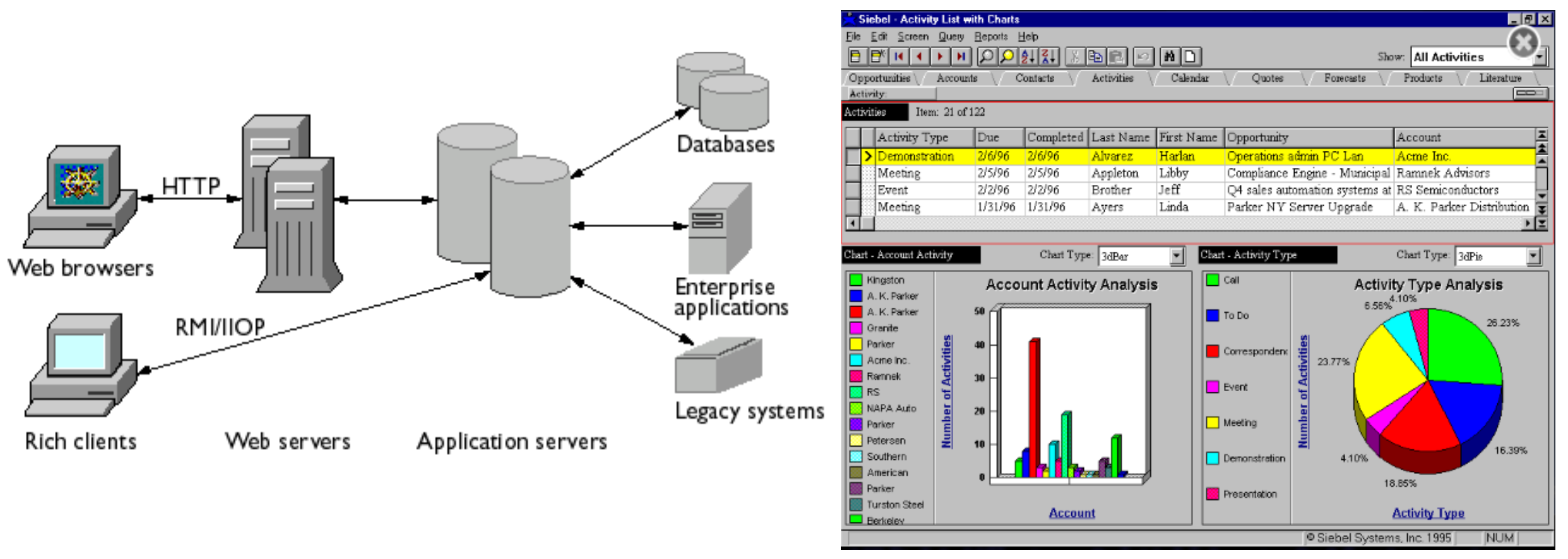
Gen2 was the age of networked enterprise software: the client-server era where applications escaped the mainframe and moved onto commodity hardware, local networks (LANs!), and increasingly distributed enterprise environments.
This was a massive unlock for the upfront capital outlay of the TCO of software systems. They no longer had to run on vertically integrated, highly specialized hardware stacks (literal “stacks”). It could run on the increasingly standardized infrastructure of the modern enterprise: servers, desktops, LANs, databases, and operating systems stitched together into a shared computational environment. The application became something a business could buy, install, administer, customize, and operate itself.
But this freedom came with a new tradeoff. Behavior became entangled with the assumptions of the operating system era and the networking era: deployment topologies, database tuning, client installs, integration plumbing, access controls, and version coordination across a growing number of components. The system was more malleable than Gen1, but also more fragile in practice. Software became easier to customize, but much harder to keep coherent over time.
Ex: Oracle, PeopleSoft, Siebel
Qualities:
- Software was deployed on commodity hardware
- Behavior became tied to proprietary OS-era (Sun, Microsoft, HP, IBM, etc.) and networking-era assumptions
- Customizations became more composable, but also more sprawling
- Upgrades required customers to install new versions and manually migrate their implementation
This is where the modern problem congealed: the genesis of the migration project.
The “implementation” had a configuration as a core. Around that accumulated integrations, scripts, custom logic, reporting pipelines, and an entire parallel universe of human procedures built in the gaps.
System migrations became indistinguishable from a migration of the actual behavior of the business itself.
Gen3 - Cloud (SaaS)
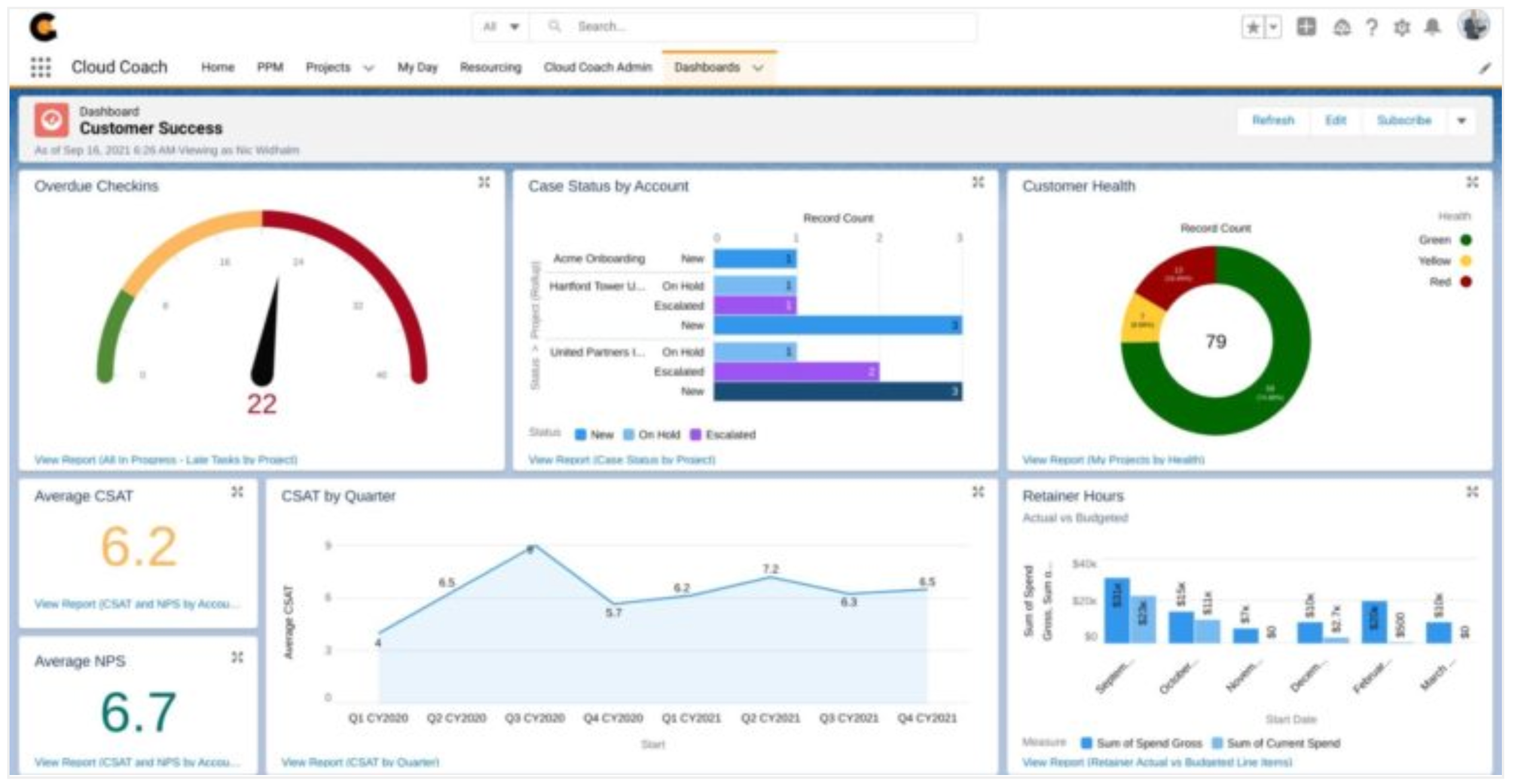
Gen3 moved enterprise software into the cloud and made distribution vastly more efficient.
Instead of shipping software for customers to install and maintain themselves, vendors operated the core application centrally and delivered it as a service. This changed the economics of deployment, upgrades, and adoption. Getting started became dramatically easier. Infrastructure burden shifted to the vendor and “managing the system” didn’t require entire full-time teams.
Ex: NetSuite, Salesforce, ServiceNow, Workday
Qualities:
- Software was deployed in the vendor’s data centers or in Big3 Public Cloud
- Upgrade rails became global, mostly invisible, with rare “forking” upgrades on entire re-platforming (e.g. Salesforce Classic → Lightning)
- Customization shifted from “change the core” to “build around the core” with open APIs and App Stores as the preferred paths for augmentation
SaaS removed a huge amount of friction from buying, deploying, and maintaining software. But it did not solve the deepest problem. The most generous interpretation is that in an effort to “clean up” we actually just mopped around the complexity into a different place.
Instead of modifying the application directly, customization got displaced into two dominant patterns:
- outside of the application via custom-built integration middleware, ETL, iPaaS (“connect my ERP to my CRM for me”)
- inside of the application via bounded development platforms, rules engines, and “approved” extension surfaces (i.e. in NetSuite these are: SuiteScript, SuiteTalk, SuiteApps)
Additionally, Vertical SaaS proliferated down-market by optimizing for time-to-value and the “Pareto case” of best practices, often by limiting composability in the data model and in the execution model entirely.
The result: this made it easy to upgrade the vendor’s product. But it did not make it easy to upgrade the customer’s implementation: the systems become stale immediately as the business processes around it changes.
Gen4 - Agentic
The lifecycle of all applications are now only bounded by compute, systems engineering, and human creativity.
We are finally able to build systems where the primary operator is not a human UI. It’s an agent. And it will revolutionize what “software” is.
Ex: Anthropic, OpenAI, Cognition, Cursor, Sierra, Serval, DOSS*←
In Gen1/2/3, the application shipped as a product, and the implementation happened as a project. Humans were the bottleneck of change in a process orchestrated through large-scale “transformation projects,” which often resulted in little transformation and big services bills.
In Gen4, the application lifecycle can become a living codebase that:
- is legible to machines and is open to humans and agents
- can be tested, refactored, deployed continuously, documented continuously
- can self-author, self-govern, and self-improve in concert with the operation of the business itself
Today we are watching the genesis of the first self-driving applications where the application and its own lifecycle have been fused together.
Gen4, Geology, and the Global 2000
55 years of Enterprise Applications are up for grabs, and the services market surrounding them is 4-5x larger than the software itself. To understand why, it helps to look at the technology stacks of the Global 2000 as a geological study.
In every prior generation, upgrades were a human motion: projects, migrations, steering committees, consultants, multi-year Gantt charts, and thousands of PowerPoint slides. Humans would do their best to coordinate, systems would fail to evolve, and implementations would inevitably ossify.
In this scenario, the original core gets buried under layers of sediment: custom fields, point-solution integrations, exception workflows, off-system spreadsheets, local scripting, policies-as-process, then process encoded as code, then code wrapped in abstraction so nobody has to touch it (or understand it).
Over years, those layers compress into something hard and fossilized, a tech stack that is a stratified record of the business at various points in time.
And in capital “E” enterprises, this geology is tectonic in formation. Generations layer, fracture, and interleave:
The standard Global 2000 enterprise runs a mix of Gen1, Gen2, and Gen3 systems. An IBM mainframe still serving core workloads. On-prem SAP/Oracle suites layered on top. Cloud SaaS fragmented across functions and domains.
Modern institutions like: G-SIBs, airlines, and hospital infrastructure are running on “Paleolithic Software” like COBOL and FORTRAN not because they’re elegant, but because the upgrade motion was a cliff that couldn't be scaled by humans. They’ve stood impregnable against every rewrite attempt, because replacing them required too much time and operational risk.
Gen4 changes the immutable law for Enterprise Software. The 10,000 ft. sheer climb of an upgrade, maintenance, support, and training motions is now scalable with compute.
The most insane part? The applications themselves are just the tip of the iceberg.
What this really means is that the value of the applications and the professional services surrounding them are all consumable by machines.
And the world of services for Enterprise Software is 4-5x larger than that of the software itself. What used to be a “cottage industry” is now civilization-scale, and the hundreds of billions of dollars are all prime surfaces for agentic automation.
OK. But how do we actually build this? What distinguishes Gen4 software systems? With Gen3 it was quite simple: the internet allows us to abstract the networked hardware and move the applications to someone else’s systems. What qualitatively makes a system AI-native / agentic?
Type I vs Type II Systems
I believe we will see a hard fork that will separate the legacy applications of yesterday and the market leaders of tomorrow.
Recently the industry discovered a kernel of truth about LLMs, and maybe intelligence in general:
- Everything must be made into “code”: because code is anything that is legible, verifiable, and ergonomic for discrete computing machines.
- If everything is code, it must be supported by a development lifecycle. An “Agentic Application-level SDLC” so to speak. Completeness means it includes: a file system, an OS / runtime, an IDE, a CI/CD pipeline, a test suite, and a cloud.
- If you build this – and then you design your processes around it, then you can scale knowledge work infinitely. There are 5-10 companies that have already pulled this off and they are growing faster than any company ever has in history.
It’s simple to sort the legacy applications of today and the transformative companies of tomorrow:
Type I Systems: Incremental, Static, Hand-Crafted.
Built to be operated via human-interfaces that can only scale and mutate through human time and effort.
This is Post-2010-era SaaS and more broadly most Enterprise Software that is Cloud-native.
The defining technical qualities are that the configuration and behavior of the product is specified in a codebase that is only operated by the publisher, deployed globally, and mostly closed-source.
Type II Systems: Evolutionary, Agentic, and Industrialized.
Built to be operated via agents inside a runtime that can evolve with compute and context.
Claude Code was the first flash of brilliance. Under the right conditions, its capabilities are blinding. They built it to be a coding tool without realizing they had uncovered the future of all applications.
The defining technical quality is that the product programmatically governs its own configuration, behavior, and lifecycle.Unlike Type I systems, Type II system behavior is defined such that:
- It lives in the platform itself
- It’s deployable per customer (locally)
- It’s open to users (human and machine)
- And it’s architected to operate, improve, and maintain itself
Agentic software is not when software can run agents. It’s that the software itself has agency over its manifestation. Self-introspection, self-authorship, self-governance, self-driving.
An arms race between Gen3 Incumbents and Gen4 Startups
Every Gen3 company is now running their own Manhattan Project to re-write their legacy Type I applications into a Type II system before competitive Gen4 startups hit escape velocity.
The incumbents will add copilots, agent builders, rules engines, orchestration layers, MCP servers, ontologies, sandboxed development platforms, and every possible “AI-native” surface known to man.
Some of these will be good. A few will be great.
But most of Gen3 will be claiming “AI fluency” in their application like a tourist claiming Spanish fluency and then proceeding to use their smartphone to ask what “dónde está la biblioteca” means.
The cause is set by a few fundamental constraints: the application ships as a fixed product, its lifecycle is not integrated into the runtime, and intelligence is accessible but not imbued. To get past these, they will have to do a complete rewrite.
We’ve seen this before. SAP and Oracle did complete rewrites to get to Cloud. PeopleSoft and Siebel didn’t.
The Master Plan
How are we approaching this arms race? To be honest - it’s the exact same as what I wrote two years ago in our “Hard Problems I” post :
- Identify the primitives hidden across fragmented business context
- Build the operating system those primitives run on.
- Express the system in a programmable, composable, modular data model that humans and agents both understand.
- Build the SDLC that lets those systems be authored, tested, deployed, and iterated on autonomously.
- Then let models drive that runtime as the first-class operators.
First we build the primitives and the operating system.
Then we build the machine that builds the machine.
And then we let the machine optimize, operate, and evolve itself.
So… what problems do we need to solve to make DOSS an AI-native, Gen4, “agentic” platform?
Hard Problems Pt. 2
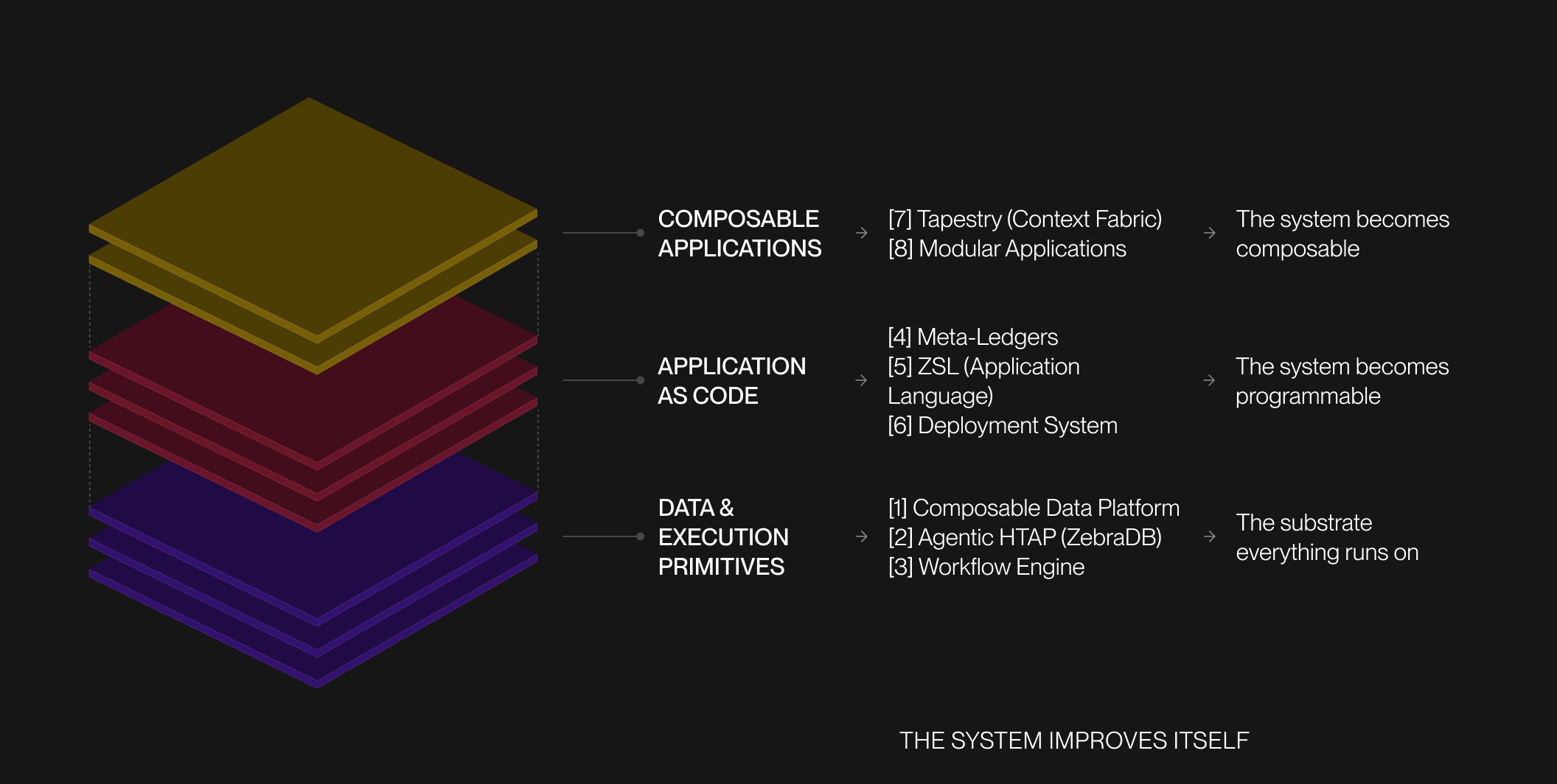
This is the updated list of hard problems: some done, some in progress. They're not independent: each is a load-bearing layer of the same structure, built from the ground up. The order is intentional.
First, we build the substrate: data and execution primitives that everything else runs on. Then we make the system programmable, so applications can be expressed, deployed, and evolved as code. On top of that, we enable composability, turning applications into modular systems instead of fixed products.
[1] Composable Data Platform. Score: 10/10 (Done).
Status: Completed
The first hard problem is building a data platform whose logical model is flexible enough to represent modern business software without a Cambrian explosion of bespoke schemas sprawling across tenants. This is our “Rosetta Stone” abstraction layer that allows the rest of the system to speak one language.
We built:
- A metadata-model control plane that can represent most enterprise applications and business process software.
- Separate experience from storage: operators and agents should work through a semantic control plane, while the storage engine remains abstracted beneath it.
- Support composability by default so entities, relationships, fields, policies, and behaviors can be recombined across modules and applications.
- Make the platform compilable so dependency graphs, lineage, and constraints are explicit rather than opaque application code.
- Treat this layer as the binding substrate across objects, workflows, ledgers, permissions, applications, and agent runtime.
Without this layer, every product becomes another crystalized application. With it, the application is now programmable.
[2] Agentic, Open-Format, Discrete HTAP. Score: 10/10.
Status: Completed
Build a storage layer and query engine that behaves as both a transactional store and an analytical warehouse and is natively ergonomic for agents. To address this our team had to create a novel architecture that we call Z-Tables (productized as ZebraDB ).
We built:
- Separate control planes (virtual) from data planes (physicalized) for both OLTP and OLAP.
- Access control around RRECBAC: Role, Resource, Entitlement, Conditions that’s implemented at the lowest possible levels (Row, Field, and Document Level Security implemented directly in DB primitives)
- “Everything is just Postgres, Everything is just SQL” as a maxim so the system remains legible, queryable, and interoperable.
- Make OLAP transactional and rely on open-format architectures. We don’t need state-of-the-art scan performance like a Databricks / Snowflake, but since it’s built on the Iceberg table format it’s simple for customers to plug in their preferred engine (Spark, DuckDB, etc) to their ZebraDB tenant.
- Agent-native. We built ZebraDB to run as an agent-native data platform where tools like Claude Code or Codex can clone, build, deploy, query, model, and migrate systems directly from CLI without a human ever having to sign-up.
The challenge is elegantly blending surfaces to make OLTP scale like a warehouse, OLAP feel transactional and real-time, and the E2E system TCO trend toward object-store economics.
[3] High-Speed Durable Execution and Workflow Engine. Score: 10/10.
Status: Completed
Enterprise processes are often expressed as “workflows”: business logic operating over large volumes of data covering complex exceptions, approvals, retries, and elegantly handled external side effects.
To properly cover this surface we have to:
- Build a workflow engine that is durable, type-safe, and high-throughput all at the same time.
- Keep it statically verifiable / compilable, so large classes of workflow errors are caught before runtime.
- Make it fast enough for real operational tasks (>100k ops/s and low-latency orchestration).
- Make it durable enough to survive restarts, retries, failures, handoffs, and long-running business processes.
- Make it cheap enough to support a very large amount of workflow volume per tenant.
If workflows are not durable and programmable, the “application-as-a-codebase” pattern breaks immediately and you just have schema and interfaces, but business logic / functions all have to live in an opaque codebase somewhere else. This is why we partnered with our friends at Restate to leverage their durable log technology, in combination with our orchestration, to make DOSS the most performant application workflow engine on the market.
[4] Meta-Ledgers. Score: 8/10.
Status: Completed
Unfortunately, everything important in enterprise software eventually converges to being a ledger in its behavior. This is why we implemented “HistoryTables” into our Z-Table architecture, such that every single table:
- Appends only, no changes.
- Tracks schema over time (provenance); therefore historicals can be queried as they were at that point-in-time, not based on current schema.
- Generates audit trails as immutable event logs: this comes for free!
[5] ZSL - The Application Language. Score: 8/10.
Status: In Progress
ZSL is the language the entire platform speaks. Every schema, workflow, interface, policy, permission, and lifecycle event is expressed through it — which means the application itself becomes a codebase that agents can read, modify, and reason about. That is what ZSL is designed for.
- Make the application feel like a codebase.
- Make the primitives of the system an emergent property of the language, not a giant hand-built taxonomy.
- Keep it type-safe so it can be statically analyzable, deterministically verifiable, and linted / type-checked through an LSP in pre-compile and the AST at compile-time (not the runtime!)
- Make ZSL the authoring surface that links data models, workflows, permissions, ledgers, and applications into one coherent system spec.
[6] Build “Terraform for the Application Layer” w/ ZSL. Score: 10/10
Status: In Progress
OK if we solve #5 - then we are left with a codebase that can’t be deployed. To successfully execute on fusing together the application, its specification, and its lifecycle, you effectively need to write a deployment toolchain like Terraform and use that to build a topological plan of a metadata graph surrounding the DSL and transactionally run it through CI/CD. Sounds easy enough.
We’re still on the fence about what should be the “source of truth”: the .zsl file itself, its AST computed into an IR, or a generated lockfile (JSON/YAML). Either way, we need to be able to go around that circle very fast and in a completely lossless manner.
Qualities:
- Build a topological understanding of the metadata graph around the ZSL configbase.
- Support agentic authoring as a first-class mode, not just human authoring.
- Perform cache invalidation on the dependency trees and handle linked graph ordering.
- Run static analysis (compile-time validation) and dynamic analysis (tests, simulations, unit checks).
- Deployments must transactionally apply schema/config changes and safely migrate downstream content, data, and workflows.
If you want to work on this one, please message us directly (wiley@doss.com / arnav@doss.com); it’s probably the “hardest 10” on this list.
[7] Building “Tapestry” our Context Fabric. Score: 10/10
Status: In Progress
While genetically unique, humans are all basically 70% water. The same claim can be made about businesses: we get a few of the primitives right and we can model their systems and context WLOG .
Tapestry is our idiosyncratic tribal knowledge modeler for the Enterprise. It’s a federated stream of context threads woven into a composite understanding of provenance, state, and consequence. Less ambiguously, it is equal parts:
- Semantic search engine
- Composite corpus of fact (statefully managed and semantically invalidated!)
- And a governed read/write access path
The end result is effectively a distributed, resilient, always accurate, shared memory, knowledge, and belief system of the Enterprise. Call notes, internal emails, external current events, first-party data stored in ZebraDB and 3rd-party data in external apps – all modeled into a graph that can be traversed algorithmically through agent/human written Cypher queries or directly embedded in latent space for reasoning applications.
[8] Composable and Modular Applications. Score: 10/10
Status: In Progress
The end state of this problem is software that can upgrade and maintain itself: a software factory, not just a software product. Getting there requires two properties working in concert: composability (separating data, workflow, permissions, logic, and presentation so the same system works for both humans and agents) and modularity (contractual boundaries that enable interoperability).The two are somewhat at odds with one another unless implemented very carefully.
Today we are working with a product that is modular and composable, but like a patchwork quilt. You can clearly see and understand the boundaries and fault lines, but in order to make changes you must carefully unstitch and restitch the system together lest you cause a snag. We need it to be more like LEGOs (which conceptually have a great API!) where everything plugs into everything with little thought and no consequences of error.
A Gen4 application cannot be a bundle of tightly coupled screens and hidden business logic. It has to be a composition of parts with clear “APIs” between them. That means each module must export and import capabilities through explicit interfaces, participate in shared routing and rendering rules, and be conditionally present without destabilizing (invalidating) the rest of the system.
Requirements:
- Modules are durable, interoperable units of ZSL config.
- Modules use import/export APIs to define what it exposes, what it consumes, and how it participates in shared state, workflow, and permissions.
- Application surfaces must be able to conditionally render modules based on configuration, context, and role without bespoke reimplementation.
- Define once; use everywhere at the application layer with componentization
- Packaging must be first-class and coherent within the ZSL filesystem and toolchain.
With #1, #2, and #5 solved, then the Composable/Modular Application can go one step further in its own agency.
In the Gen3 Cloud-native SaaS world (not to pick on someone, but think Salesforce!), tenant customization is bad because it breaks the upgrade path. Every deviation from the base product creates a compounding maintenance burden. With our Gen4 architecture, this customization becomes maintainable because it is expressed inside the same application-as-code system as the core product.
Imagine DOSS ARP is on v1.1. A customer deploys this and then makes changes, creating v1.1-a.
Then the platform ships an update bumping everyone to v1.2. A Gen3 system treats that as a painful upgrade problem where certain features will not work as intended. A Gen4 system treats it as an application-level configbase merge.
The platform should be able to:
- compare v1.1 → v1.1-a
- compare v1.1 → v1.2
- understand the graph-space transformations between those states
- generate a candidate merged system then run automated testing and validation
- and finally route the result into human review (if that’s even required!)
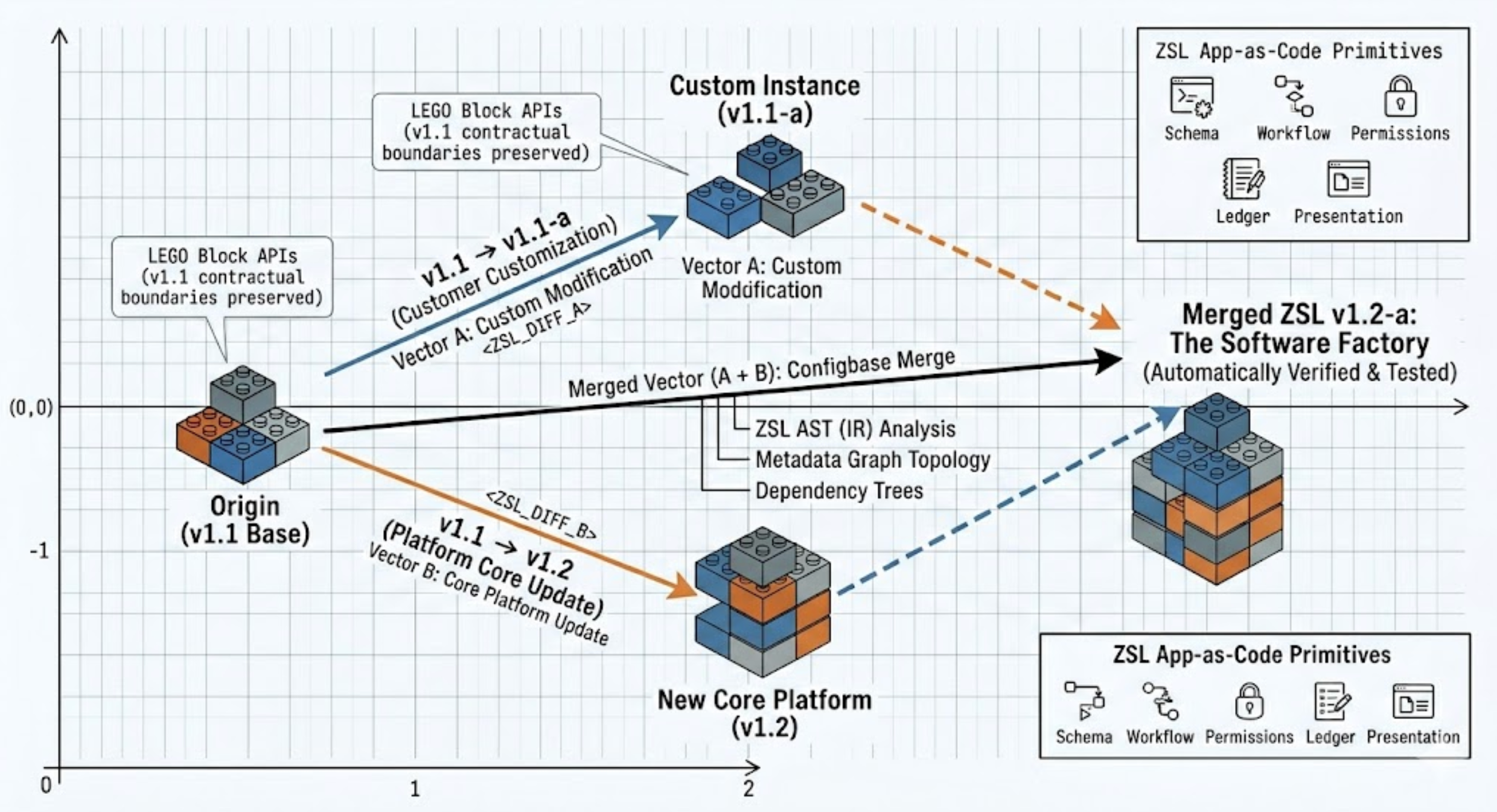
Composability+Modularity delivered in an agentic application lifecycle is the mechanism that makes it self-maintaining, and why every layer below it was worth building.
Conclusion
At DOSS, we believe the next generation of enterprise software will be defined by this fundamental truth: the lifecycle of the application will merge with the application itself.
That inversion only becomes real if data, workflows, ledgers, language, context, deployment, modularity, and reasoning are rebuilt as one coherent system. That is what these hard problems are really about: charting a course from a better version of Gen3 SaaS to a Gen4 Operations Cloud that is natively agentic.
The future arrived faster than we anticipated and the prize is larger than we imagined. Now it’s time to build. If this resonates with you, we’re hiring .