Before my co-founder Wiley and I had locked down our MVP product build, the first commits I made to our codebase were the foundations of our codegen pipeline.
As the system has evolved, we’ve found so much value in the core architecture pattern, and we regularly find ourselves describing the implementation to others during dinners and tech talks.
As they say, explain it twice, document it. I’m finally putting into writing how we use codegen as the foundation for our AI-native ERP.
The Power of Codegen

The power of codegen has been evident to me for a very long time.
- When I was doing my master’s at UIUC, I had a college internship at Uber. I’ll never forget taking down an entire data center’s traffic with my first deployment — all I did was rename a variable in a Thrift server, but without proper integration testing, the rename didn’t update every caller. Tribal knowledge + testing are not the answer!
- When I was building at Rubrik, the scaffolding for auth and our APIs was generally built entirely with codegen from an extremely simple set of YAML files. This meant new developers could get up and running extremely fast.
- As a founding engineer at Siteline, I entered into a world of GraphQL plugin-based codegen that allowed a centralized, typed authority on your resolver definitions to unify your backend and frontend.
Through this journey, I came to realize that enterprise software doesn’t usually fail because teams can’t write code. It fails because the system drifts. Your database schema says one thing. Your API contract says another. Your resolvers, loaders, ETL logic, CDC wiring, and frontend types each encode their own partial truth.
At first, this feels manageable. Then the product grows. Then velocity drops. Then reliability drops. Then everyone starts asking why “simple changes” take weeks or cause instability.
At DOSS, we made a different decision: treat codegen as infrastructure, not a developer convenience. Our GraphQL schema isn’t just an API definition. It’s a source language. Our codegen layer is the compiler.
From one set of GraphQL files, we generate the core runtime surfaces of the platform: database models, resolver contracts, data loading boundaries, graph sync types, typed client operations, and migration metadata.
The Real Problem: Cross-Layer Drift
Most tech stacks are assembled layer-by-layer over time:
- DB models
- API schema
- service code
- background workers
- frontend contracts
- migration logic
Every layer introduces one more place to drift. Every drift introduces hidden coupling. Every hidden coupling increases implementation risk.
The classic response is “better process”: more reviews, stricter checklists, more documentation. That helps, but process does not remove the root issue: too many sources of truth. As developers, we generally remember that we should prevent multiple source of truth in the database; but far too often we fail to do the same in our sprawling codebases.
At DOSS, we wanted the opposite:
- one core schema language
- many generated targets
- deterministic outputs
- fewer hand-written glue layers
The goal is not to eliminate engineering judgment. The goal is to eliminate avoidable inconsistency and tedium.
Schema-First at DOSS
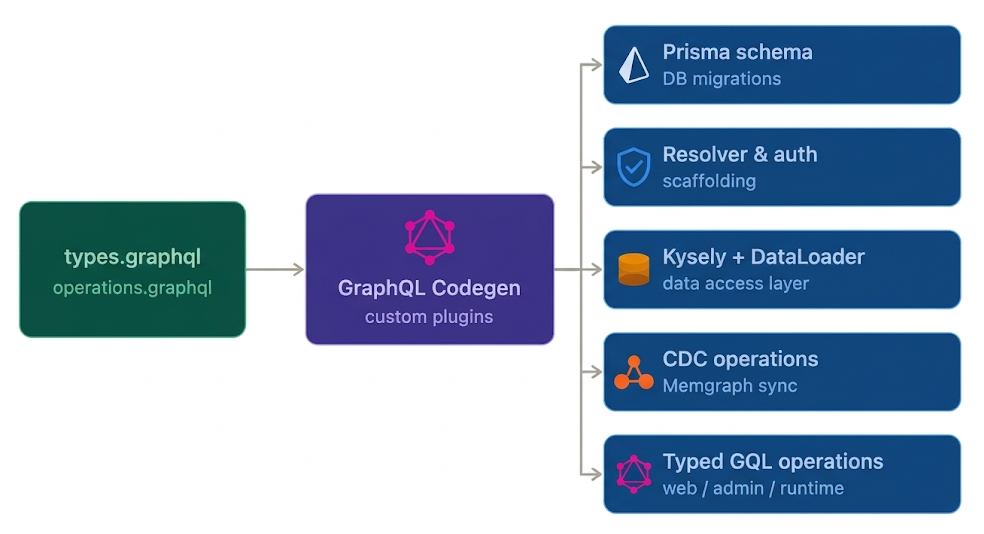
At DOSS, our types.graphql and a set of service-level operations.graphql files define the platform contract. From there, our codegen pipeline emits multiple targets across the monorepo.
This is orchestrated through the GraphQL Code Generator plus custom plugins. The pipeline compiles into:
- A unified Prisma schema that, in turn, drives generated database up/down migrations
- API resolver and authorization check scaffolding
- A custom typed Kysely client for building complex SQL queries
- CDC operations to keep our graph database, Memgraph, in sync
- A custom DataLoader factory to improve query performance
- Typed GraphQL operations for web, web-admin, and runtime services
- And much more
In other words: this is not just “generate frontend hooks.” It is a multi-target compile step for core platform behavior.
Multi-Target Compilation in Practice
GraphQL was designed as a typed language, so plugins can parse the schema and generate code. GraphQL Codegen parses your .graphql schema into an AST (abstract syntax tree). Once the schema is in a tree, you can run custom logic (called plugins in GraphQL world) against the AST and output generated code into new files.
1. Database model generation (Prisma)
We generate our schema.prisma file from GraphQL types and directives, including relation mapping, archived models, and enum mappings.
That does two things:
- keeps DB shape aligned with product contract
- makes schema changes explicit in one place
2. Resolver and contract generation
Resolvers for our GraphQL endpoints are generated for all our servers with target-specific auth and context wrappers. Input typings, validation scaffolding, authz implementation stubs, and resolver interfaces are generated together so the implementation stays aligned.
This is especially important in a large monorepo with a growing engineering team: nobody is guessing what “the expected resolver shape” is.
3. Data access generation
We generate both:
- Kysely database typings
- DataLoader creation logic for entity and relation patterns (including bypass-RLS where required)
That means we encode loading patterns and relation semantics off our schema, instead of hand-authoring hundreds of repetitive loader paths.
4. Graph runtime generation (Cypher + CDC)
A lot of ERP value lives in the relationship of the schema of the organization’s business applications and workflow context, not just rows in a table.
From the same schema foundation, we can generate:
- Cypher node/relation typings
- CDC operations to keep the graph database in sync
This keeps Postgres-origin data and graph representations in a consistent compile chain.
5. Consumer-facing typed artifacts
Frontend applications are able to consume the generated typed operation artifacts. We can prevent the classic “stringly-typed” GraphQL calls and remove the need for copy-pasted response assumptions.
That closes the loop from schema to execution so that front-end and back-end engineers can operate in lockstep off a single control plane.
Schema-Driven Migration Synthesis
One of the more important parts of this stack is that we don’t stop at “types.”
We also generate migration metadata and SQL from our core GraphQL system:
- DB constraints
- CDC publications
- Soft deletion flows for archiving data
These plugins read schema directives/state, diff against existing generated metadata, and produce versioned migration artifacts when changes are detected. That gives us a safer path for evolving behavior that stays tied to schema + generation rules.
This Is Still Engineering, Not Magic
Codegen gets dismissed when it’s used as boilerplate reduction. That’s not all this is. At this depth, codegen requires strong compiler-like discipline:
- deterministic plugin behavior
- clear target boundaries
- stable naming and relation rules
- strict generation ownership
- safe migration semantics
- zero ambiguity around generated vs hand-written code
The classic response we hear today is “my agent will write this for me, so I don’t need codegen.” While it is true that background token spend can often solve the problem of tedium, in reality, that is both a misuse of tokens and a non-deterministic approach to a highly deterministic system.

AI agent magic should be the driver of authorship into a deterministically constructed inner system.
Beyond GraphQL: The Same Pattern Shows Up Elsewhere
The same design philosophy we use with GraphQL has surfaced in other parts of our stack:
- Formula language parser generation via ANTLR grammar
- i18n type generation from translation resources to ensure we have full internationalization coverage of all languages
- etc.
Different domains, same idea: treat interfaces and grammars as source languages, then compile target-specific artifacts. Once you internalize this, “codegen” stops being a devex utility, and instead becomes a core architectural layer.
The long-term vision for our software development pipeline is straightforward. As agents become the primary authors of code, we want to simplify the process to allow them to simply write intent once. Then, that will drive compilation downstream to keep the system legible as it scales. This allows encoding best practices and keeping the system uniform.
This is how we think modern systems should be built.