On the other side of a very hard problem is a very big opportunity.
Looking for a thread to pull
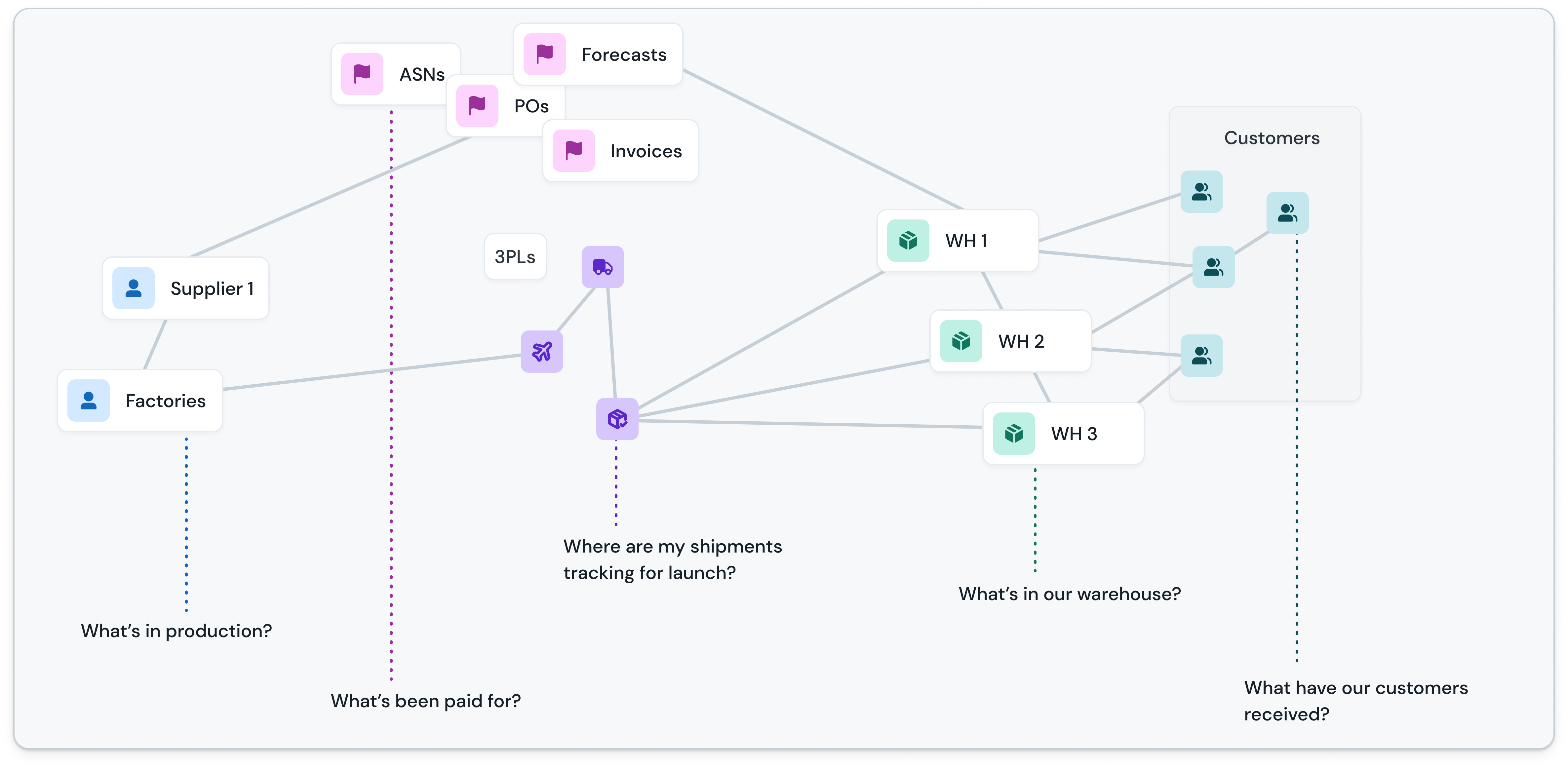
When I set out to work on DOSS , it began as a naive act. I wanted to make it simpler for businesses to manage their physical operations. Keeping tracking of inventory, purchase orders, invoices, their product catalog, and so on. But, the more I pulled on the thread of this the idea, the more it unraveled. I found myself looking back in time, through the history of information theory, the beginnings of computing, and even back to the origins of bookkeeping in Ancient Mesopotamia.
The deeper I went, the more I realized that there were foundational assumptions about software that could be challenged in ways that hadn't been possible before.
For the first time ever, we could use machines to synthesize vast amount of context and distill this down into an information model that mirrors the real world—all without having to lift a finger. Here's what this looks like at DOSS:
- Use LLMs to identify primitives across pools of contextual data
- Construct an OS with modular and hardened primitives (building blocks like LEGOs) accessible as text-based schemas
- Model the entire system as graph-based Workflows so that the relationships can be understood visually (by humans and by machines)
- Create a transpiler layer between the real-world representations and the software. This means we can speed-run a typical ERP implementation by 100x.
- Introduce LLMs-in-the-loop as their own modular primitives. Capable of adjudicating workflows, leveraging other primitives as tools, and even allowing them to augment / modify themselves.
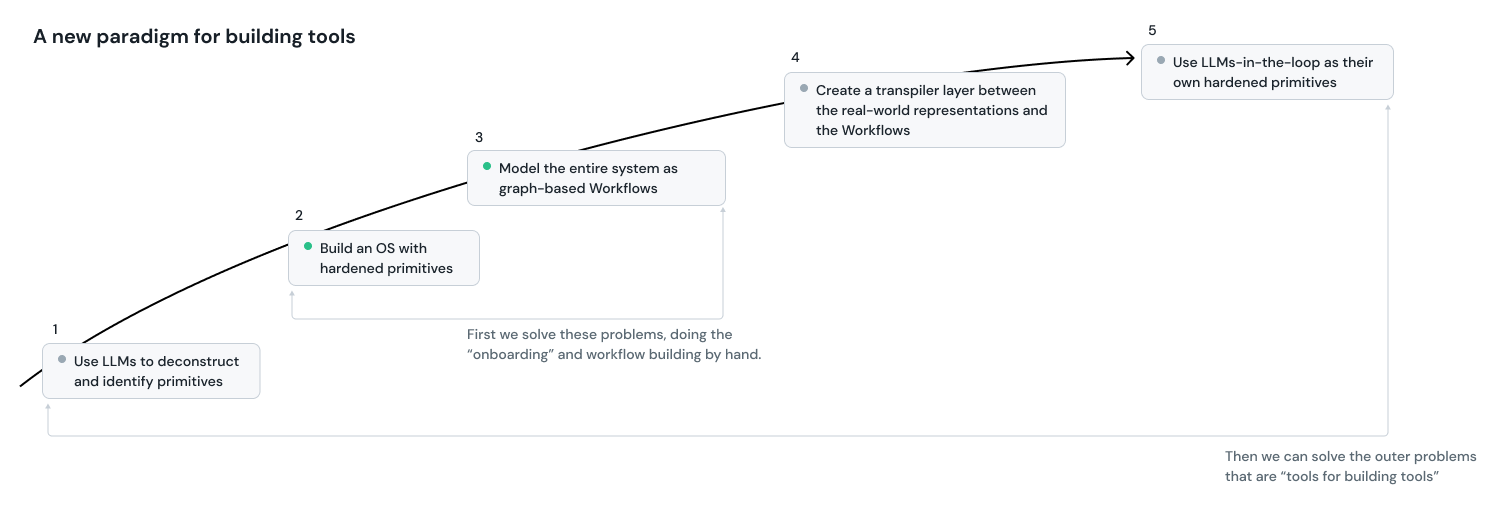
This can be distilled down to two distinct concepts:
- First, we build "the machine" (#2 and #3 from above). This requires very high quality software engineering and systems design. We've already made great progress on this.
- Next, we build the "the machine that builds the machine" (#1, #4, #5 from above). This will require clever fine-tuning and data infrastructure to allow for state-of-the-art language models to be able to reference the syntax of our primitives as if it were just another programming language.
We're going need to build multiple companies worth of products into one platform and do it fast enough so that we can productize a playground for the agentic AGI workers that will be arriving by the end of the decade. The other competitors in this race are formidable. The incumbents in the ERP market have been around for 30-40 years, make tens of billions of dollars a year, and have one of the lowest churn customer segments in all of software.
In my eyes, this is a 10 out of 10 on the difficulty scale. What else could I look to for inspiration as we went out and tackled this problem?
My formal education, along with the bulk of my work experience, comes from working on hardware. I’m not an expert on what constitutes as a “hard problem” in software but some areas that come to mind for me are 10/10 are things like:
- Google Search infrastructure (BigTable, Spanner, etc)
- OpenAI training data pipeline
- the Figma editor rendering pipeline ( this post is a great example of a micro-cosmic facet of how hard it is)
- Real-time trading platform execution systems
- AWS S3 core services (somehow it gets better every year )
- high-workload streaming platforms (Netflix, YouTube)
- Uber’s pricing, routing, and mapping systems ( old blogs from Uber Engineering)
While there are more examples, the common theme among these is that they operate at the outer limits of what is considered feasible. They often encounter physical world limitations, such as semiconductor fabrication below a 4nm process, which is tantamount to manipulating discrete atoms.
Now, let's put this into perspective with our "difficulty scale." It's a hand-wavy logarithmic scale, not scientifically precise but approximating the order of magnitude of difficulty. You rate a problem based on the solution space that surrounds it when executed almost perfectly. This nuance, using terms like "almost perfect" or "almost optimal," offers a perspective on the problem's complexity.
Making an "almost perfect" omelet is significantly less challenging than crafting an "almost perfect" 3D ray-casting engine. We need to squint at the solution to give ourselves a good idea of how hard it really is.
With these definitions in mind, let's move on to the exciting part.
How to take a big swing
I like doing hard things, but within specific guidelines. The parameters basically are:
- Is it a knowable problem? Like scientifically falsifiable? Can you define a solution? (i.e. I’m uninterested in asking questions about the origin of the universe)
- Am I in a strong position to take on this problem?
I don’t think you can go straight to solving 10/10 problems as a startup. It’s just too risky. You’re telling me with a finite amount of money and time, you want to start by working on an unknowable and maybe-intractable problem? There’s a reason that a company like OpenAI was founded as a non-profit. It gave them the latitude to traverse the idea maze of something that might be intractable.
I’ve heard others describe this as “earning the right to take on the big problems”. Rarely, can any group of people go straight for the biggest opportunity from the outset. More often a methodical and compounding approach is what works — where overcoming each problem gives you the capabilities to take on the next.

So, in order for us to get to the really good stuff (the 10/10s), we have to selectively construct a path that gives us the time and resources to able to take shots at the biggest problems.
At DOSS, we have a roadmap document that lists of hundreds of “tasks” (problems) that comprise the totality of our aspirations to the extent that I’ve been able to write them down. That number will certainly grow before it begins to shrink. I’ve outlined some of these baskets of problems in hopes that someone reading this will jump out of their chair and say:
“Oh my god, I need to work on this!”
What are we building at DOSS?
- A visual flowchart style “workflow editor” that allows us to manipulate first-party and third-party data via primitives exposed as nodes in the flowchart.
Score: 8/10
This is hard to do well and requires an extremely thoughtful data model architecture for reliable step execution and reusable 3rd-party and 1st-party building blocks. I’m basically saying “rebuild Zapier’s entire product inside of our product” but make the whole thing schema-driven so that we can make it play nicely with the rest of our platform.
- Core Tables optimizations and the Tables IDE. Tabular data is that foundation of our product and it’s actually shockingly difficult to build a bunch of primitives that contain the familiarity of Excel and the typing and performance of SQL. We’ve barely scratched the surface of this.
Score: 5/10
Hard, but a lot of people have done this and something that there is a lot of existing open source software showing off best practices. This one punches above it’s weight in terms of impact because there is a barbell distribution of the utility of tabular data. On one side, everyone needs a simplified no-code Airtable-like type-safe data grid where they can link together data. On the other end, every growing business has a snowballing data footprint that they wrangle in some warehouse like Snowflake, Segment, AWS, etc. There is a very real opportunity for us to make Doss the best place for businesses to operationalize their data warehouses and CDPs.
- PDF generator templating and data manipulation. This one is grotesque and I wish it wasn’t on here but it is. Our users just really need this (which is equally unfortunate for them as it is for us) and we could make a hacky one very easily. But we don’t do hacky, so we have to make it amazing.
Score: 6/10
It’s just a nasty piece of work because PDFs are just a poorly constructed technology that were only meant to allow for packaging documents in a printable container. It seems like people end up just writing their own image manipulation pipeline and layer it over a base PDF and inject in variables. There’s some shortcuts that we can take to make this more manageable - I want us to build something so good that it changes my mind about PDFs.
- DOSS Data Model Abstraction Layer (DDMAL). I don’t know how to come up with a better name for this but basically the idea is that we need to make the data model of our product (DOSS Data Model AKA the “DDM”) something that users can interact with in a legible manner. Many products have started exposing their “data graph” or “fields and properties” in a visual editor of sorts. We’re going to do the same thing but within a few twists that make it better (field linking, workflow ingress / egress, process visualization, and more listed later on).
Score: 8/10
This abstraction layer will be how our product interacts with itself and simultaneously provides a view of “what is setup in a DOSS instance”. Architecting this will require a shape rotator with abilities far beyond mine.
- Tokenization of everything in the DDM (see above). The idea here is users just type “@” and get access to a lot of their data model as tokenized objects that get linked around and their context can be manipulated.
Score: 5/10
Hard to do it WLOG but a lot easier if we do a good job on the DDMAL. Have to think about retrieval, type-safety, making it context injectable everywhere (in comments, in tabular data, in documents, in workflows, and on). Also, how we manage resource control when you federate access with RBAC being layered on top.
- Ledgers, Journals, and Cost Accounting primitives
Score: 6/10
Hard because we’ll have to learn this all from scratch and we need to make it play nicely with all of our other primitives and the DDM. Easy because the rules all exist in a bunch of books. The hardest part will be figuring out how to expose the concepts of LIFO / FIFO and queuing in a way that “Just Works”. I'm excited about this one.
- Advanced Formula editor
Score: 5/10
Hard to do well but lots of great examples out there and with Typescript we can roll a lot of this ourselves using their native AST, especially with well placed tokenization and DDMAL implementation.
- Event stream manager
Score: 6/10
We need the ability to manage the inflow and outflow of 3rd party data, user input information, asynchronous jobs, etc. across a complex data where every node is connected to N more nodes. The usual way of solving this is a complex job scheduler or event stream manager that takes in relatively ambiguous and disparate concepts as events and takes myriad actions on them. Long term, the graph of information the events act on will not only be contained within a single customer organization, but will also link data across the entire web of companies that work together.
Every time I mention "Kafka" the team shudders, but that will change in due time.
- Latent Context Engine. Again, I’m not sure what to call this because it’s a pretty abstract idea that I have only seen properly executed in a few places. It’s more of a pump that takes latent pools of context and recirculates. A context percolator? The premise is simple: we use the parameters of objects in the data model to infer data about other objects. i.e. events A and B are followed by C. Later on we see a and then b and infer c and surface to the user.
Score: 8/10.
This seems really hard to do well, but again it’s built on top of the DDAML and can be accessed within our visual workflow editor! Compounding product concepts.
This is something that other companies like Affinity have executed on very well and many new age CRMs are using as the foundation for their products — however they’re pretty much always hardcoded in. Creating a more general purpose Context Engine is going to become a tractable problem for the first-time ever.
- DDM generation and manipulation from plain-text and latent context pools.
Score: 10/10
I think this is our first real ten, thought it might be a soft one and closer to a 9. The basic premise is that we build a human-to-machine plain-text translation layer between the DDMAL and the interfaces that our users access that allows them to generate and manipulate objects in the DDM. In my opinion, this would ultimately be our “breakthrough” or “actualization” of a differentiated approach to tool building with software that I have not seen executed to fruition.
We could allow users to select context actively and instruct the product to “do XYZ given this”. Others have built product around seeds of this concept of this but I think this approach is truly novel:
- First to create an operating system and contextual file system of references using primitives like tabular data, formulas, graphs, metrics, forms, workflows steps, etc
- Second, it all can be generated, manipulated, augmented, reconfigured, via plain-text and via itself
What does that last point mean “via itself”? Well, the idea here is that meta instruction is simple when the DDMAL provides workflow steps that can access “workflow steps” or however we encapsulate this concept.
Imagine the following: We could easily create a workflow that looks at incoming messages over email, gets attachments, and finds relevant records to add them to with summaries of the email chains. Once we’ve created this workflow, what if we also created another workflow step which looks at all of our active integrations and our email and identifies when we start using a new product (looking through our email) that could have useful workflows in DOSS just like this. Maybe we also want to aggregate Slack messages or forms submitted on Hubspot. It will auto-draft a workflow and auto-draft the integration to authenticate and we (actual human users!) can edit it before publishing.
This is just an example but you can easily imagine this for scenarios where every time you add some new tool that you have to go back and reconfigure everything across different workflows and identify the scope. Between this data model awareness concept + our DDMAL visualization from earlier, we can give users unprecedented legibility and maintainability of systems that would have been completely FUBAR in prior generations.
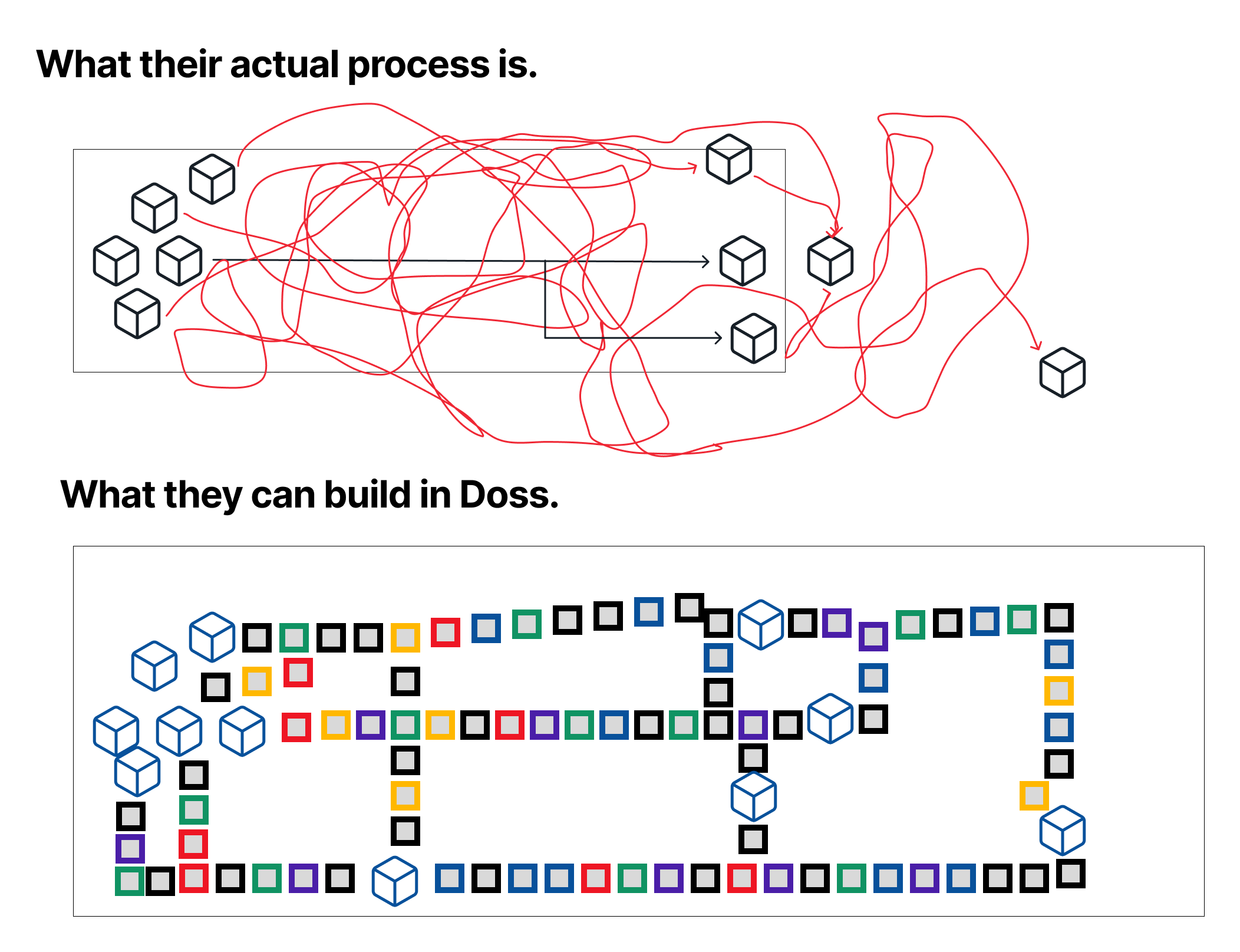
--
If you're still reading this, I want you to message me and tell me about yourself. I'm interested in meeting anyone who's this excited by building elegant enterprise software.
Also - we're hiring for Software Engineers, Designers, and Growth Managers at our San Francisco office. Please add me on LinkedIn to learn more.