Remember sweating through Context-Free Grammars (CFGs) in that CS theory class you swore you'd never need again? Turns out, those theoretical foundations became the secret weapon behind building an Excel-like formula engine that scales to millions of rows without breaking a sweat.
At DOSS , we needed to solve a deceptively complex problem: how do you let users write sophisticated formulas across dynamic, interconnected business data while maintaining the performance and reliability of a production system?
Making Formulas Feel Natural
The first hurdle was creating a Domain Specific Language (DSL) that would feel familiar to anyone who's used Excel, but powerful enough to handle complex business logic across multiple data sources. We needed something that could express relationships like:
SUM(FILTER(Orders, Status = "Shipped" AND ShipDate > TODAY() - 30)) / COUNT(DISTINCT(Customers))
But in a system where "Orders" and "Customers" aren't predetermined tables—they're whatever schema the customer has configured.
Our approach leveraged those CS theory fundamentals:
1. Design a Comprehensive CFG: We mapped every possible expression into a context-free grammar that could handle nested functions, complex conditionals, and cross-table references.
2. Live Linting with CodeMirror: As users type, the context flows through our editor, surfacing syntax errors and type mismatches in real-time—just like a modern code editor.
3. Parse with ANTLR: User input gets converted to an Abstract Syntax Tree (AST), which we traverse to translate each node into DOSS primitives for execution.
The result is a formula system that feels intuitive to use but maintains the rigor needed for mission-critical business operations. Users can express complex business logic without worrying about the underlying technical complexity.
The Scale Problem: When Formulas Meet Big Data
Having a working formula engine is one thing. Making it work at enterprise scale is another challenge entirely. Our customers aren't dealing with small datasets—they're processing millions of rows across dozens of interconnected tables, with formulas that reference multiple data sources and perform complex aggregations.
Initially, we explored the obvious solutions:
- Elasticsearch: Great for search and analytics, but falls apart with the complex joins required for relational formula execution
- Data Warehousing: Solutions like ClickHouse or Snowflake could handle the scale, but they're heavyweight solutions requiring significant infrastructure investment and performance scales with data volume
- Stream Processing: Apache Flink and similar frameworks offer real-time processing, but with complexity that would overwhelm a small platform engineering team
None of these felt right for our use case. We needed something that could scale without requiring a dedicated data engineering team to maintain.
The SQL Generation Approach
Our first production solution was a SQL code generator that converted DOSS formulas into optimized database queries. This approach had several advantages:
- Leveraged existing PostgreSQL infrastructure
- Maintained ACID properties for data consistency
- Kept the complexity contained within our existing codebase
For many use cases, this worked beautifully. Complex formulas that might require multiple API calls or manual data processing could be resolved with a single, optimized query.
But even this elegant solution hit walls at scale. When customers started processing datasets in the six-to-seven-figure row counts, query performance became unpredictable. Complex formulas that worked fine on smaller datasets would timeout on larger ones.
Enter Materialize: Incremental Computation at Scale
The breakthrough came when we discovered Materialize —a streaming engine built on concepts from Timely Dataflow and Differential Dataflow. This wasn't just another part of infra bloat; it was a system designed specifically for maintaining complex, derived materialized views over changing data.
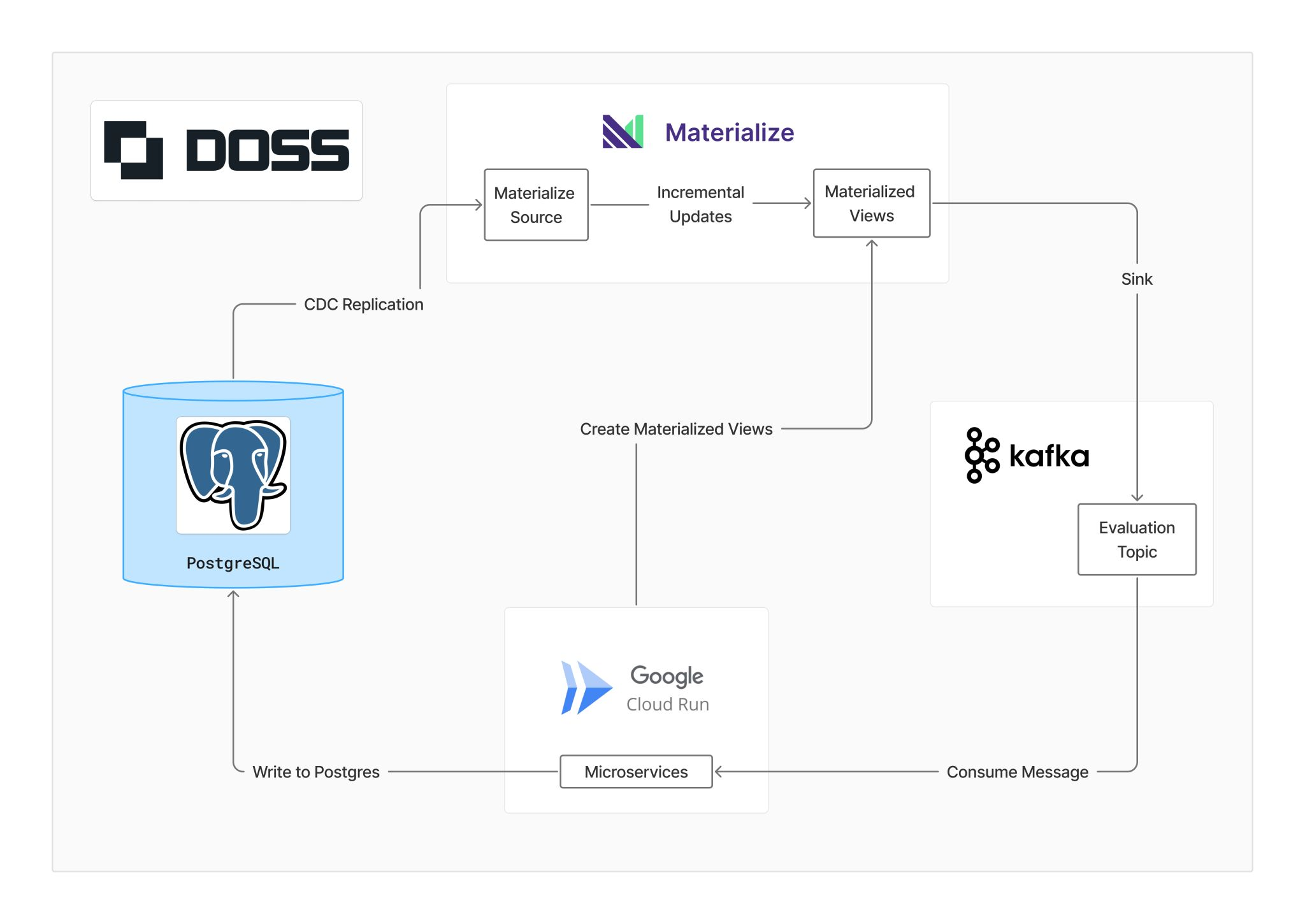
Here's how it works in our system:
1. Change Data Capture: We replicate changes from our main PostgreSQL database to Materialize using CDC (Change Data Capture).
2. Materialized Views: Complex formulas are pre-computed as materialized views that automatically update when underlying data changes.
3. Incremental Updates: Here’s the banger. Instead of recomputing entire formulas from scratch, Materialize calculates only the incremental changes needed to update results.
The performance improvements were dramatic. Formulas that previously took minutes to compute on large datasets now complete in under a second—even at 10,000x the scale.
"It Just Works"
This technical foundation enables something crucial for our customers: predictable performance regardless of scale. When a business grows from thousands to millions of records, their formulas continue working without requiring infrastructure changes, query optimization, or performance tuning.
One of our customers recently told us: "We chose DOSS because no matter how big we get, we have no doubts about the system—it just works without us thinking about the underlying setup."
That's exactly what we're aiming for. The technical complexity of scaling formula computation across millions of rows should be invisible to users who just want to understand their business metrics.
The Composability Advantage
The real power of our approach is both performance and composability. Because formulas are parsed into ASTs and executed through our graph-based data model, they can reference data across the entire business schema, not just within predetermined tables.
Users can write formulas that:
- Reference data from any connected system
- Perform complex aggregations across multiple data sources
- Maintain relationships as business schemas evolve
- Scale transparently as data volumes grow
This creates a formula system that grows with the business rather than constraining it.
The Theoretical Foundation Pays Off
Those CS theory classes that seemed so abstract actually provided the conceptual framework for solving real production problems. Context-Free Grammars gave us the structure to build a reliable parser. Differential Dataflow concepts enabled incremental computation at scale. SQL-Code Gen provided the bridge between user intent and system execution.
The lesson isn't that every theoretical concept will directly apply to production systems—it's that understanding the fundamental principles gives you a toolkit for solving novel problems. When off-the-shelf solutions don't fit your use case, theoretical foundations help you design custom solutions that actually work.
What's Next: AI-Powered Formula Generation
We're exploring how to extend this foundation with AI-powered formula generation. Instead of users needing to learn our DSL syntax, they could describe their business logic in natural language and have the system generate the appropriate formulas.
The CFG foundation makes this possible—we can validate AI-generated formulas against our grammar, ensure they're syntactically correct, and provide real-time feedback on their logical structure.
The future of business intelligence is systems that are both intuitive to use and capable of handling enterprise-scale complexity.